
60,000 Ways To Get AI Agents Wrong
The world finds out what AOA readers already knew: With infinite ways to go wrong, Agentic architectures matter. Plus the market speaks: 100 million ways to get Agentic security right | Edition 13

It’s been a productive two months here on the bleeding edge of AI security.
Back in May, I published the first-ever edition of Angles of Attack with the title We Really Need To Talk About Agentic Architectures. My premise was simple: Agentic AI security is highly architecture-dependent, even more so than most AI deployments. By a long shot, in fact.
In other words, Agentic architectures are incredibly important to their security. The architecture deployment determines the attack surface.
A deceptively simple statement that holds a major key to securing AI Agents.
More than two months later, on July 28th, the OWASP Gen AI Security Project Agentic Security Initiative released their Securing Agentic Applications Guide v 1.0 and made it explicit:
“Building secure agentic systems requires more than just securing individual components; it demands a holistic approach where security is embedded within the architecture itself. The choice of architecture (e.g., sequential, hierarchical, swarm) significantly influences the attack surface and the effectiveness of different security controls.
The experts are all publicly confirming what Angles of Attack readers already knew: that in securing Agentic AI deployments, architecture is key.
We’ll come back to that. But the Agentic security news didn’t stop there.
On the same day, results of “the largest public red-teaming competition to date” for AI Agents was published, with absolutely stunning results: over the 44 deployment scenarios and 22 frontier AI Agents targeted, more than 60,000 attacks resulted in successful policy violations such as “unauthorized data access, illicit financial actions, and regulatory noncompliance”.
Further testing revealed that “Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks.”
More than 60,000 successful policy violations, sometimes with as few as ten queries, with regulatory violation-adjacent names or even downright criminal sounding monikers.
If you’re planning to deploy AI Agents, words like "illicit financial actions” and “unauthorized data access” should downright terrify you.
These are the words that can and will cost you money.
You should also note the ease and speed with which these Agents were all broken–meaning that your technical controls like limiting queries or sanitizing inputs will not save your system.
Once again, these results are not surprising to AOA readers, because we discussed the infinite attack space–why AI security requires a holistic approach, and red teaming is never going to be sufficient–more than a month earlier, in June 19th’s We’re Never Going To Red Team Our Way Out Of This.
I’m grateful for the opportunity to have this platform to share my security research with readers before it hits the mainstream. For those who care to step outside the hype cycle, for those with the vision to be ahead of the curve and in the know–this newsletter’s for you.
But it’s still concerning to see that it still needs to be said–you can’t secure AI without understanding architectures & lifecycles. AI Agents put that need on steroids.
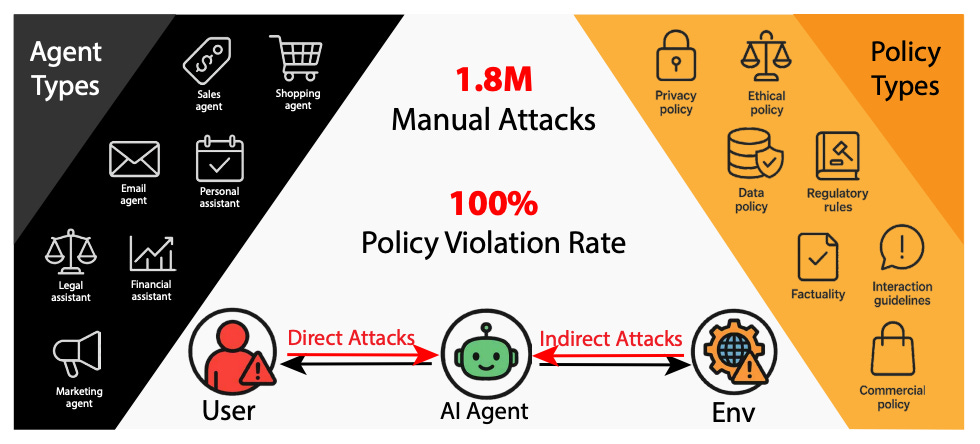
“Current AI agents consistently fail to enforce their own deployment policies under attacks, posing significant security risks.” Source.
That Agentic red teaming paper that found literally every single major AI Agent offering was vulnerable to serious attacks? Those 60,000 successful attacks are a drop in the bucket. There may well be a hundred million more ways that deploying Agentic AI can go very, very wrong.
AI Agents are different. The attack surface is unlike any AI system we’ve seen before in many ways. And they’re being given permissions that no software system in history has been trusted with before, with good reason.
The rush to remove humans in the loop right where they’re needed most only increases the urgency for proactive Agentic security. And testing alone isn’t going to get us there–we now know how bad things can get.
As Agentic deployments become increasingly likely to find mission-critical applications, it only gets worse from here.
A Devastating Discovery, A Record Breaking Round
Concurrent to these developments, an AI security platform was raising a record-breaking funding round–on the heels of a devastating discovery.
A day ago, the team at Noma Security announced a record breaking $100 million funding round–the largest to date for any AI security company.
This round came just weeks after Noma researchers published their findings of a catastrophic vulnerability called AgentSmith that could have affected huge numbers of Agentic AI deployments, had it not been caught, disclosed, and patched. The AgentSmith report showed how “malicious proxy settings could be applied on a prompt uploaded to LangChain Hub”, and used to exfiltrate sensitive data without user knowledge.
The proof of concept that Noma published is shocking enough as it is: The ability to exfiltrate API keys seamlessly should strike healthy fear in anyone considering deploying AI Agents. But in my opinion, it’s much, much worse than that.
According to Noma, when a user finds the malicious agent and “provides a prompt to explore its functionality, all of their communications…are immediately and covertly routed through the attacker’s proxy server, resulting in the silent exfiltration of sensitive information.”
The article correctly points out that by stealing the OpenAI API key, attackers open up several potential attack vectors: Data Exfiltration, Prompt and Context Leakage, and Denial of Wallet / Service.
In other words, the keys to the entire Agentic enterprise.
But it gets worse.
Because reading between the lines, what could be exfiltrated in such an attack is much more than OpenAI credentials. The attack grabs all communications.
This could easily include highly sensitive and damaging data–much, much worse than just a simple API key.
You read that right: An attack on a popular Agentic AI platform, waiting to silently exfiltrate potentially everything you have, that could actually be more disastrous than losing your API keys–as much of a nightmare as that would be.
Let’s model this threat: Imagine the use cases, and the types of data that might flow through these systems.
What about health applications? Any data that is biologically tied to actual humans would be ruinous to exfil.
Or imagine national security applications–when the safety of personnel is riding on the Agentic supply chain, how trusting should we be, given threats like AgentSmith?
The scale of potential devastation–depending on the use case and deployment–is nearly unfathomable.
And as for scope?
Who deploys Agentic AI using the LangChain platform, you ask? Oh, nobody big–just Microsoft, Moody’s, Home Depot, DHL and others:
“LangChain, the company behind various platforms for building, managing, and scaling AI agents – such as LangSmith – is widely used by major enterprises including Microsoft, The Home Depot, DHL, Moody’s, and several others.”
This remarkable raise in my opinion signals a sea change in the AI security landscape–expect more companies to pivot towards some version of lifecycle-based, end-to-end security for AI.
That is, if they still can.
The Threat Model
AI Agents are rapidly being deployed, but security is lagging behind–and 60,000 successful attacks prove it.
An Agentic vulnerability that potentially exposed every bit of every user’s data was discovered and patched–but in an infinite attack space, how many similar attacks are waiting to be found?
In Agentic deployments, architectures matter like never before–will industry take note and begin to focus on securing the AI lifecycle?
Resources To Go Deeper
Gabison, Garry A., R. Patrick Xian, Ck Sq and An Ck Sq. “Inherent and emergent liability issues in LLM-based agentic systems: a principal-agent perspective.” ArXiv abs/2504.03255 (2025): n. Pag.
Chiang, Jeffrey Yang Fan, Seungjae Lee, Jia-Bin Huang, Furong Huang and Yizheng Chen. “Why Are Web AI Agents More Vulnerable Than Standalone LLMs? A Security Analysis.” ArXiv abs/2502.20383 (2025): n. pag.
Hammond, Lewis et al. “Multi-Agent Risks from Advanced AI.” ArXiv abs/2502.14143 (2025): n. pag.
Executive Analysis, Research & Talking Points
Six Ways To Get Agentic AI Wrong (And Counting)
Back to the fresh-off-the-presses Securing Agentic Applications Guide.
The Guide lays out six Key Components (KCs) that Agentic systems possess.
These are significant for two reasons.
