
How Anthropic Failed Agentic–Again
Anthropic’s unfunny joke of a system card, how Agentic devs are assuming all the risk, and what to do about it | Edition 35


Photo: Me, circa this morning. Breaking Agents in some hotel, somewhere in or around Washington DC.
Anthropic’s Claude Opus 4.5 is supposed to be their flagship proto-Agentic offering–but Anthropic’s release fails anyone deploying Agentic AI.
It doesn’t just fail–it fails hard.
And the reason why is right in the very system card that’s supposed to help ensure its security.
To understand why this all matters, let’s back up. Or rather, rewind: Back to a time when something called a system card was a rarity, and the history of these disclosures was only just beginning.
What’s A System Card–And Why It Matters
A system card might disclose things like data, bias, and other testing metrics.
For example, a system card might contain disclosures about the gender composition of a dataset for training a facial recognition model.
In the early days of AI development–we’re talking about your so-called “classical” machine learning–some of the most prominent AI safety, ethics, and security researchers were calling for more disclosure of the technical underpinnings of AI systems.
AI system cards are one way of addressing this need.
What I mean by “classical machine learning” here is anything that predates the popularization of GenAI systems, like LLMs.
This includes computer vision systems (like the ones that read package labels and sort mail, or the facial recognition example from above).
It also includes the predictive AI systems that still power much of our critical infrastructure and national security.
If you’re not familiar with GenAI’s capabilities–and limitations–it’s maybe tempting to believe that “classical” AI systems are an obsolete relic of the past. This is absolutely not the case.
In addition to paving the way for the GenAI systems that emerged and became popular in 2022, Predictive AI (PredAI) systems also influenced every aspect of operationalization for LLMs.
And if that wasn’t enough–as previously mentioned, these PredAI systems continue to power mission-critical applications in everything from power grids, to nuclear reactors, to commercial aviation.
And these are systems which cannot be replaced with LLMs.
So PredAI still matters in very practical ways in the industry.
There is, believe it or not, one more salient point to reiterate here: The vulnerabilities that plague PredAI/classical ML/whatever you want to call it, also affect GenAI.
They’re the same vulnerabilities.
Despite what the shiny new names suggest, the math has never changed.
When it comes to AI security, there is functionally no difference between GenAI and “classical” AI, except in use cases. Keep that in mind.
Why this matters: Because the effectively infinite attack space for all AI systems comes into play when we’re evaluating their security.
Back to the historical note: System cards weren’t always de rigueur in the industry.
In the earliest move-fast-and-break-things days of AI development, one of the biggest hurdles to AI systems making it into production–and staying online–was the lack of serious documentation.
This is still the case today.
You might be wondering what shifted the tide in industry.
I can answer this: Nothing.
Nothing significant has changed to move the needle for most teams developing or planning to deploy AI, in my experience. System documentation remains a critical issue.
AI security, responsibility, ethics, and explainability experts have begged the industry for years to make system cards (as well as datasheets, FMEAs, and other serious engineering implements) a normalized part of AI development best practices.
Not just for “explainability” purposes–but to be able to understand system behavior, chart bias, trace data lineages, and provide any type of security whatsoever.
The real crux of the issue: AI systems operate at scale. Agentic systems even more so–and any system designed to automate at scale, with minimal human oversight, requires clear and extensive documentation.
It’s only logical.
The more automation, the greater the risk. The less human oversight, the greater the risk. The greater the scale, the greater the risk.
As visibility decreases, and risk increases, documentation must increase as well.
It makes perfect sense.
And yet, industry remains behind. And this is one reason why so many AI projects never make it into production–or return any ROI.
Why have the big model providers started doing what appears to be the “responsible” thing, by issuing system cards with their model releases?
I’ll leave that as an exercise to the reader. Or maybe I’ll just state that in my opinion, it rhymes with “ethics washing”.
Either/or.
Because when you look at the system card for Anthropic’s latest Agentic candidate, it’s hard to take it seriously as anything approaching rigorous security research.
How Anthropic’s System Card Fails Agentic Developers & Deployers
The system card idea was meant to provide some type of systematized documentation that developers could access for crucial information about an AI model’s training and functioning.
Ideally this would also contain the results of adversarial testing.
And this is where we run into problems.
I could list about a hundred, but here’s a major vector where Anthropic’s latest system card fails anyone who is developing or deploying with Agentic systems:
First, note that the initial probing into Opus 4.5’s security vulnerabilities, is a paltry one hundred fifty (150) attacks. Or what Anthropic calls “malicious coding requests”.
One hundred and fifty. 150.
This for a model which, like every other AI model in existence, operates with a 25-dimensional adversarial subspace, and a list of potential attacks nearing infinity.
And they’re doing 150?
In case you’re keeping score, 150 is less than infinity.
How much less? Honestly, it’s difficult to say. But what we do know is that it’s a lot less than the number of potential attacks.
While Anthropic claims that the model rejected 100% of these several (lol) attempts, it’s hard to take this bananas metric in any way seriously given the actual mathematics of the attack surface.
And this is evident as the model’s performance degrades over increasingly Agentic tasks and behaviors. Claude Code’s performance on this already ridiculous test degrades sharply: As per The Verge:
When tested to see whether Opus 4.5 would comply with “malware creation, writing code for destructive DDoS attacks, and developing non-consensual monitoring software,” the model only refused about 78% of requests.
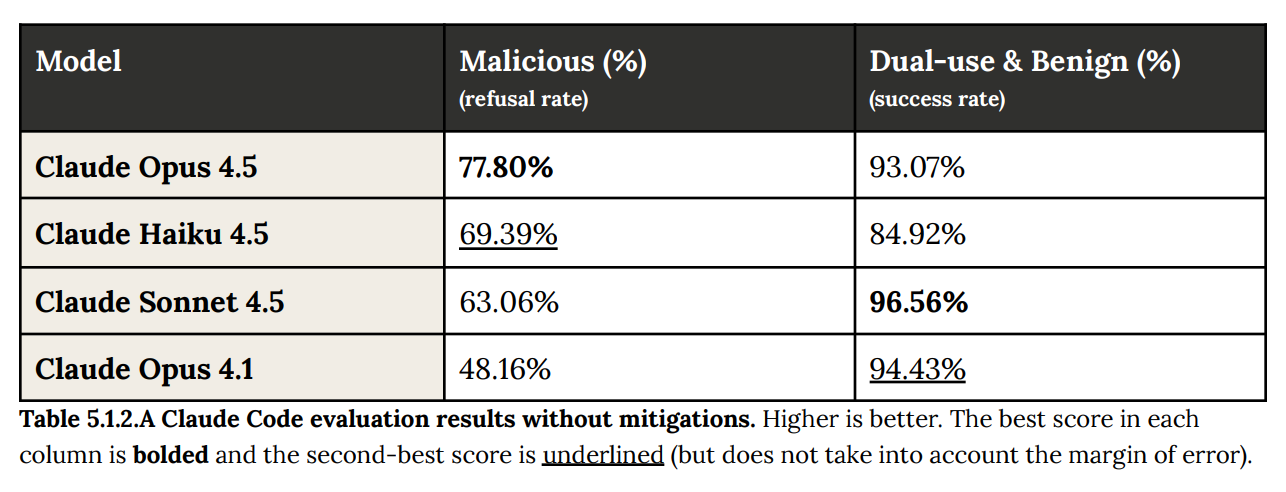
Image: Table from Anthropic’s Claude Opus 4.5 system card.
Why did this performance degrade? Because A) the test was a joke, and B) for Agentic systems, architectures matter.
Why do architectures matter so much for Agents? Because they can both cause & predict the ways that failures cascade.
Somehow Anthropic either appears to have missed that memo–or hopes that their customers did.
I know which one I think it is.
Because it gets even worse: Claude code was tested with only 49 malicious prompts.

Image: Screencap from Anthropic’s Claude Opus 4.5 system card.
Are They Serious?
How any serious security researcher could pass this off as a reasonable test is beyond me.
It’s honestly bizarre that this is presented with an apparently straight face, like we literally did 17 tests on our earth-shattering technology before releasing it, very cool right?
No guys, sorry: Either your tech does not shatter paradigms, or else you need to do more than 5 minutes worth of “research” into its safety & security.
Pick a lane.
We are once again back to the move-fast-and-break-things mentality when it comes to security for these systems–meanwhile the developers want to be taken seriously, like they’re the grown ups in the room when it comes to AI safety.
Again, a lane must be picked here. It cannot be both.
You cannot front an office full of chill dudes who are too cool for real AI security as also somehow the most expert and serious of engineers.
If you’re going to put on security theater, we demand a show. 150 attacks isn’t going to cut it.
I’m saying it: This isn’t even good security theater. And we’re not buying it anymore.
Stay frosty.
The Threat Model
System cards were intended to provide actionable information about AI models in production; not ethics- or security-washing.
In a nearly infinite attack space, 150 test attacks isn’t going to cut it–and in Agentic deployments where failures cascade, even the test results themselves point to the ineffectiveness.
Testing Agentic systems requires an acknowledgement of the mathematics of their training, and the scale of their deployments–anything less is (bad) security theater.
Resources To Go Deeper
Pavlova, Maya, Erik Brinkman, Krithika Iyer, Vítor Albiero, Joanna Bitton, Hailey Nguyen, Joe Li, Cristian Canton-Ferrer, Ivan Evtimov and Aaron Grattafiori. “Automated Red Teaming with GOAT: the Generative Offensive Agent Tester.” ArXiv abs/2410.01606 (2024): n. Pag.
Suggu, Sri Keerthi. “Agentic AI Workflows in Cybersecurity: Opportunities, Challenges, and Governance via the MCP Model.” Journal of Information Systems Engineering and Management (2025): n. Pag.
Janjusevic, Strahinja, Anna Baron Garcia and Sohrob Kazerounian. “Hiding in the AI Traffic: Abusing MCP for LLM-Powered Agentic Red Teaming.” (2025).
Executive Analysis, Research, & Talking Points
Why Anthropic’s Testing Fell Apart With Agentic
The deeper into Agentic functionality Anthropic’s tests went, the worse the model performed. Here’s why, and what it means for deployers (and breakers):
